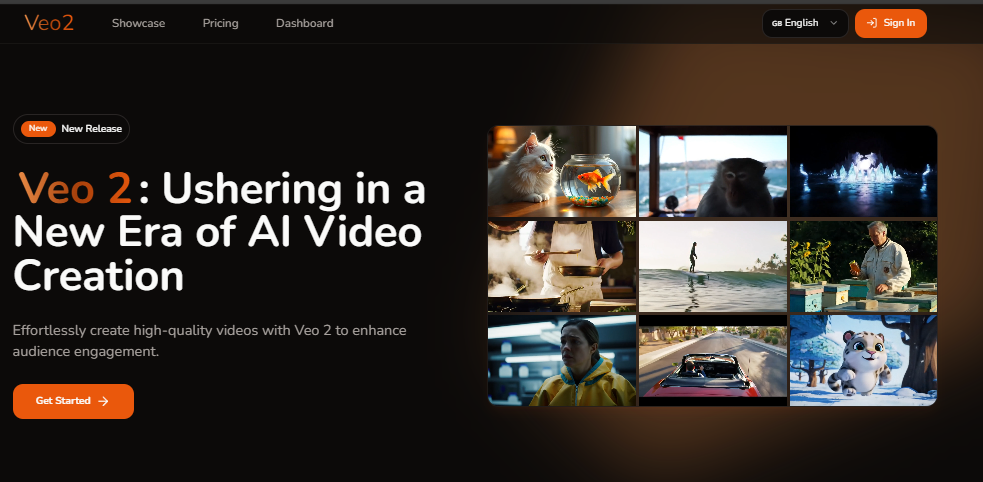
Veo 2 是由谷歌旗下 DeepMind 公司于 2024 年 12 月推出的新一代人工智能视频生成模型,旨在通过先进的技术突破重新定义 AI 视频创作的质量与控制标准。以下是其核心特点及相关信息的综合介绍:
高分辨率与长时长
- 支持生成最高 4K 分辨率(4096×2160 像素)、最长 2 分钟的视频片段,分辨率较 OpenAI 的 Sora 模型提升 4 倍,时长增加 6 倍。
- 输出细节丰富,减少常见的视觉伪影(如多余肢体、模糊场景)。
精准物理模拟与镜头控制
- 能逼真模拟运动、流体力学、光影效果及人类表情,实现复杂动作的自然流畅表现。
- 支持专业级镜头指令,如广角、特写、无人机视角、浅景深等,可生成多样化的电影风格。
多模态输入与创意自由度
- 支持文本提示或参考图像生成视频,同时处理简单与复杂指令,灵活适配不同视觉风格(如实景、卡通、复古等)。
- 通过人工评估,其在 Movie Gen Bench 基准测试中表现优于其他主流模型。
- 内容创作:适用于 YouTube 短视频、企业宣传片、广告创意等,快速生成高质量素材。
- 影视制作:辅助电影概念验证、特效预览及虚拟场景搭建,降低拍摄成本。
- 教育与科普:模拟科学实验、历史事件重现,增强教学直观性。
- 虚拟现实(VR):为虚拟旅游、沉浸式体验提供逼真的动态内容。
- 连贯性与一致性:生成复杂场景或快速动作时可能出现细节偏差,需进一步优化。
- 访问限制:初期通过 Google 的 VideoFX 平台开放测试,仅限美国 18 岁以上用户申请,且实际输出限制为 720p、8 秒内。
- 深度伪造风险:采用 SynthID 水印技术嵌入隐形标记,确保内容可追溯性。
- DeepMind 计划在 2025 年逐步扩展功能,支持更长视频、更高分辨率,并集成到 YouTube Shorts、Vertex AI 等平台。
- 通过用户反馈持续迭代模型,提升复杂场景处理能力及生成稳定性。
Veo 2 凭借 4K 级画质、物理模拟能力及专业镜头控制,成为 AI 视频生成领域的标杆产品。尽管仍存在技术局限性,但其在创意产业、影视制作等领域的潜力已引发广泛关注,未来有望推动视频创作的智能化革新。
(注:信息综合自 DeepMind 官方声明及权威媒体报道,具体功能以实际发布版本为准。)